Bellman equation
A Bellman equation (also known as a dynamic programming equation), named after its discoverer, Richard Bellman, is a necessary condition for optimality associated with the mathematical optimization method known as dynamic programming. It writes the value of a decision problem at a certain point in time in terms of the payoff from some initial choices and the value of the remaining decision problem that results from those initial choices. This breaks a dynamic optimization problem into simpler subproblems, as Bellman's Principle of Optimality prescribes.
The Bellman equation was first applied to engineering control theory and to other topics in applied mathematics, and subsequently became an important tool in economic theory.
Almost any problem which can be solved using optimal control theory can also be solved by analyzing the appropriate Bellman equation. However, the term 'Bellman equation' usually refers to the dynamic programming equation associated with discrete-time optimization problems. In continuous-time optimization problems, the analogous equation is a partial differential equation which is usually called the Hamilton-Jacobi-Bellman equation.
Contents |
Analytical concepts in dynamic programming
To understand the Bellman equation, several underlying concepts must be understood. First, any optimization problem has some objective--- minimizing travel time, minimizing cost, maximizing profits, maximizing utility, et cetera. The mathematical function that describes this objective is called the objective function.
Dynamic programming breaks a multi-period planning problem into simpler steps at different points in time. Therefore, it requires keeping track of how the decision situation is evolving over time. The information about the current situation which is needed to make a correct decision is called the state (See Bellman, 1957, Ch. III.2).[1][2] For example, to decide how much to consume and spend at each point in time, people would need to know (among other things) their initial wealth. Therefore, wealth would be one of their state variables, but there would probably be others.
The variables chosen at any given point in time are often called the control variables. For example, given their current wealth, people might decide how much to consume now. Choosing the control variables now may be equivalent to choosing the next state; more generally, the next state is affected by other factors in addition to the current control. For example, in the simplest case, today's wealth (the state) and consumption (the control) might exactly determine tomorrow's wealth (the new state), though typically other factors will affect tomorrow's wealth too.
The dynamic programming approach describes the optimal plan by finding a rule that tells what the controls should be, given any possible value of the state. For example, if consumption (c) depends only on wealth (W), we would seek a rule 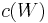 that gives consumption as a function of wealth. Such a rule, determining the controls as a function of the states, is called a policy function (See Bellman, 1957, Ch. III.2).[1]
that gives consumption as a function of wealth. Such a rule, determining the controls as a function of the states, is called a policy function (See Bellman, 1957, Ch. III.2).[1]
Finally, by definition, the optimal decision rule is the one that achieves the best possible value of the objective. For example, if someone chooses consumption, given wealth, in order to maximize happiness (assuming happiness H can be represented by a mathematical function, such as a utility function), then each level of wealth will be associated with some highest possible level of happiness, 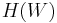 . The best possible value of the objective, written as a function of the state, is called the value function.
. The best possible value of the objective, written as a function of the state, is called the value function.
Richard Bellman showed that a dynamic optimization problem in discrete time can be stated in a recursive, step-by-step form by writing down the relationship between the value function in one period and the value function in the next period. The relationship between these two value functions is called the Bellman equation.
Deriving the Bellman equation
A dynamic decision problem
Let the state at time t be 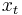 . For a decision that begins at time 0, we take as given the initial state
. For a decision that begins at time 0, we take as given the initial state 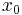 . At any time, the set of possible actions depends on the current state; we can write this as
. At any time, the set of possible actions depends on the current state; we can write this as 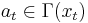 , where the action
, where the action 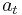 represents one or more control variables. We also assume that the state changes from x to a new state T(x,a) when action a is taken, and that the current payoff from taking action a in state x is F(x,a). Finally, we assume impatience, represented by a discount factor 0<β<1.
represents one or more control variables. We also assume that the state changes from x to a new state T(x,a) when action a is taken, and that the current payoff from taking action a in state x is F(x,a). Finally, we assume impatience, represented by a discount factor 0<β<1.
Under these assumptions, an infinite-horizon decision problem takes the following form:
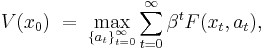
subject to the constraints
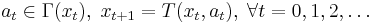
Notice that we have defined notation 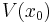 to represent the optimal value that can be obtained by maximizing this objective function subject to the assumed constraints. This function is the value function. It is a function of the initial state variable , since the best value obtainable depends on the initial situation.
to represent the optimal value that can be obtained by maximizing this objective function subject to the assumed constraints. This function is the value function. It is a function of the initial state variable , since the best value obtainable depends on the initial situation.
Bellman's Principle of Optimality
The dynamic programming method breaks this decision problem into smaller subproblems. Richard Bellman's Principle of Optimality describes how to do this:
Principle of Optimality: An optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision. (See Bellman, 1957, Chap. III.3.)[1][2][3]
In computer science, a problem that can be broken apart like this is said to have optimal substructure. In the context of dynamic game theory, this principle is analogous to the concept of subgame perfect equilibrium, although what constitutes an optimal policy in this case is conditioned on the decision-maker's opponents choosing similarly optimal policies from their points of view.
As suggested by the Principle of Optimality, we will consider the first decision separately, setting aside all future decisions (we will start afresh from time 1 with the new state 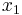 ). Collecting the future decisions in brackets on the right, the previous problem is equivalent to:
). Collecting the future decisions in brackets on the right, the previous problem is equivalent to:
![\max_{ a_0 } \left \{ F(x_0,a_0)
%2B \beta \left[ \max_{ \left \{ a_{t} \right \}_{t=1}^{\infty} }
\sum_{t=1}^{\infty} \beta^{t-1} F(x_t,a_{t}) \; \; s.t. \; \;
a_{t} \in \Gamma (x_t), \; x_{t%2B1}=T(x_t,a_t), \; \forall t = 1, 2, \dots \right] \right \}](/2012-wikipedia_en_all_nopic_01_2012/I/65e59be1f59506ccb13fdfeb8b67cc54.png)
subject to the constraints
Here we are choosing 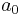 , knowing that our choice will cause the time 1 state to be
, knowing that our choice will cause the time 1 state to be 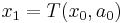 . That new state will then affect the decision problem from time 1 on. The whole future decision problem appears inside the square brackets on the right.
. That new state will then affect the decision problem from time 1 on. The whole future decision problem appears inside the square brackets on the right.
The Bellman equation
So far it seems we have only made the problem uglier by separating today's decision from future decisions. But we can simplify by noticing that what is inside the square brackets on the right is the value of the time 1 decision problem, starting from state .
Therefore we can rewrite the problem as a recursive definition of the value function:
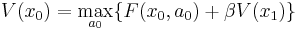 , subject to the constraints:
, subject to the constraints: 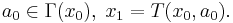
This is the Bellman equation. It can be simplified even further if we drop time subscripts and plug in the value of the next state:
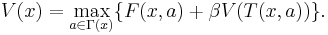
The Bellman equation is classified as a functional equation, because solving it means finding the unknown function V, which is the value function. Recall that the value function describes the best possible value of the objective, as a function of the state x. By calculating the value function, we will also find the function a(x) that describes the optimal action as a function of the state; this is called the policy function.
The Bellman equation in a stochastic problem
Dynamic programming can be especially useful in stochastic decisions, that is, optimization problems affected by random events. For example, consider a problem exactly like the one discussed above, except that  is a random variable, which may be influenced by and , but is not determined by them exactly. We can describe this case by defining the probability distribution conditional on and , for example,
is a random variable, which may be influenced by and , but is not determined by them exactly. We can describe this case by defining the probability distribution conditional on and , for example,
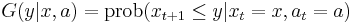
Given this probability law determining conditional on and , the Bellman equation can be written as
![V(x) = \max_{a \in \Gamma (x) } \left \{F(x,a) %2B \beta E_G [V(y)|x,a] \right \},](/2012-wikipedia_en_all_nopic_01_2012/I/dc7315934fbfd8740219e9a80e12d8c7.png)
where 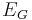 represents a conditional expectation under distribution G.
represents a conditional expectation under distribution G.
Solution methods
- The method of undetermined coefficients, also known as 'guess and verify', can be used to solve some infinite-horizon, autonomous Bellman equations.
- The Bellman equation can be solved by backwards induction, either analytically in a few special cases, or numerically on a computer. Numerical backwards induction is applicable to a wide variety of problems, but may be infeasible when there are many state variables, due to the curse of dimensionality.
- By calculating the first-order conditions associated with the Bellman equation, and then using the envelope theorem to eliminate the derivatives of the value function, it is possible to obtain a system of difference equations or differential equations called the 'Euler equations'. Standard techniques for the solution of difference or differential equations can then be used to calculate the dynamics of the state variables and the control variables of the optimization problem.
Applications in economics
The first known application of a Bellman equation in economics is due to Martin Beckmann and Richard Muth.[4] Martin Beckmann also wrote extensively on consumption theory using the Bellman equation in 1959. His work influenced Edmund S. Phelps, among others.
A celebrated economic application of a Bellman equation is Merton's seminal 1973 article on the intertemporal capital asset pricing model.[5] (See also Merton's portfolio problem).The solution to Merton's theoretical model, one in which investors chose between income today and future income or capital gains, is a form of Bellman's equation. Because economic applications of dynamic programming usually result in a Bellman equation that is a difference equation, economists refer to dynamic programming as a "recursive method."
Stokey, Lucas & Prescott describes stochastic and nonstochastic dynamic programming in considerable detail, giving many examples of how to employ dynamic programming to solve problems in economic theory.[6] This book led to dynamic programming being employed to solve a wide range of theoretical problems in economics, including optimal economic growth, resource extraction, principal–agent problems, public finance, business investment, asset pricing, factor supply, and industrial organization. Ljungqvist & Sargent apply dynamic programming to study a variety of theoretical questions in monetary policy, fiscal policy, taxation, economic growth, search theory, and labor economics.[7] Dixit & Pindyck showed the value of the method for thinking about capital budgeting.[8] Anderson adapted the technique to business valuation, including privately-held businesses.[9]
Using dynamic programming to solve concrete problems is complicated by informational difficulties, such as choosing the unobservable discount rate. There are also computational issues, the main one being the curse of dimensionality arising from the vast number of possible actions and potential state variables that must be considered before an optimal strategy can be selected. For an extensive discussion of computational issues, see Miranda & Fackler.,[10] and Meyn 2007[11]
Example
In MDP, a Bellman equation refers to a recursion for expected rewards. For example, the expected reward for being in a particular state s and following some fixed policy  has the Bellman equation:
has the Bellman equation:
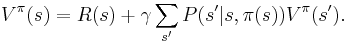
This equation describes the expected reward for taking the action prescribed by some policy .
The equation for the optimal policy is referred to as the Bellman optimality equation:
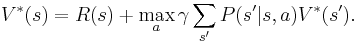
It describes the reward for taking the action giving the highest expected return.
See also
- Dynamic programming
- Hamilton-Jacobi-Bellman equation
- Markov decision process
- Optimal control theory
- Optimal substructure
- Recursive competitive equilibrium
References
- ^ a b c Bellman, R.E. 1957. Dynamic Programming. Princeton University Press, Princeton, NJ. Republished 2003: Dover, ISBN 0486428095.
- ^ a b S. Dreyfus (2002), 'Richard Bellman on the birth of dynamic programming' Operations Research 50 (1), pp. 48-51.
- ^ R Bellman, On the Theory of Dynamic Programming, Proceedings of the National Academy of Sciences, 1952
- ^ Martin Beckmann and Richard Muth, 1954, "On the solution to the fundamental equation of inventory theory," Cowles Commission Discussion Paper 2116.
- ^ Robert C. Merton, 1973, "An Intertemporal Capital Asset Pricing Model," Econometrica 41: 867-887.
- ^ *Nancy Stokey, and Robert E. Lucas, with Edward Prescott, 1989. Recursive Methods in Economic Dynamics. Harvard Univ. Press.
- ^ Lars Ljungqvist & Thomas Sargent, 2004. Recursive Macroeconomic Theory. MIT Press.
- ^ Avinash Dixit & Robert Pindyck, 1994. Investment Under Uncertainty. Princeton Univ. Press.
- ^ Anderson, Patrick L., Business Economics & Finance, CRC Press, 2004, ISBN 1584883480; The Value of Private Businesses in the United States, Business Economics (2009) 44, 87–108. doi:10.1057/be.2009.4.
- ^ Miranda, M., & Fackler, P., 2002. Applied Computational Economics and Finance. MIT Press
- ^ S. P. Meyn, 2007. Control Techniques for Complex Networks, Cambridge University Press, 2007. Appendix contains abridged Meyn & Tweedie.